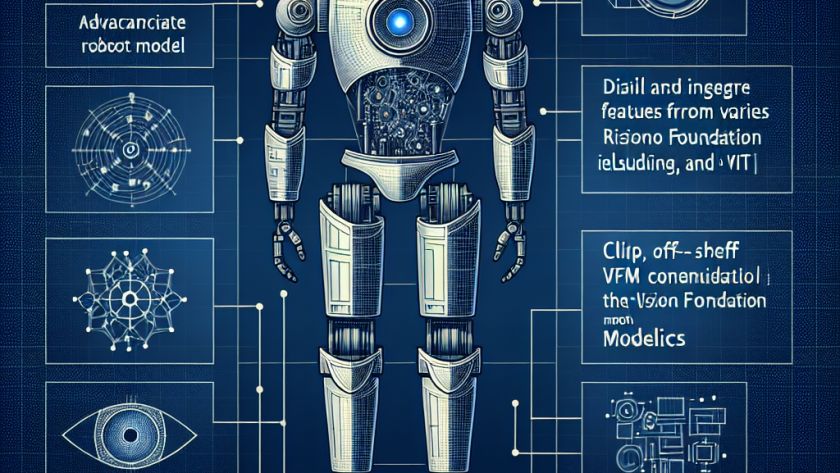
OWLSAM2 is an innovative project that combines the strengths of OWLv2 and SAM2, two advanced models in the field of computer vision, to create a text-promptable model for zero-shot object detection and mask generation. OWLv2 stands out for its zero-shot object detection abilities that enable it to identify objects based on textual descriptions alone, without…